
Iriton's log
[SQLD] 데이터 모델과 SQL 본문
*본 포스트는 '유선배 SQL개발자 과외노트' 도서를 참고하여 작성되었습니다.
01. 정규화
데이터 정합성(데이터의 정확성과 일관성을 유지하고 보장)을 위해 엔터티를 작은 단위로 분리하는 과정
정규화 할 경우 데이터 조회성능은 처리 조건에 따라 향상되는 경우도 있고 저하되는 경우도 있다. 근데 입력, 수정, 삭제 성능은 일반적으로 향상된다.
하지만 그렇다고 모든 엔터티를 무작정 분리하면 안 된다. 따라서 일정한 룰이 존재한다.
제1정규형
- 모든 속성은 반드시 하나의 값만 가져야 한다.
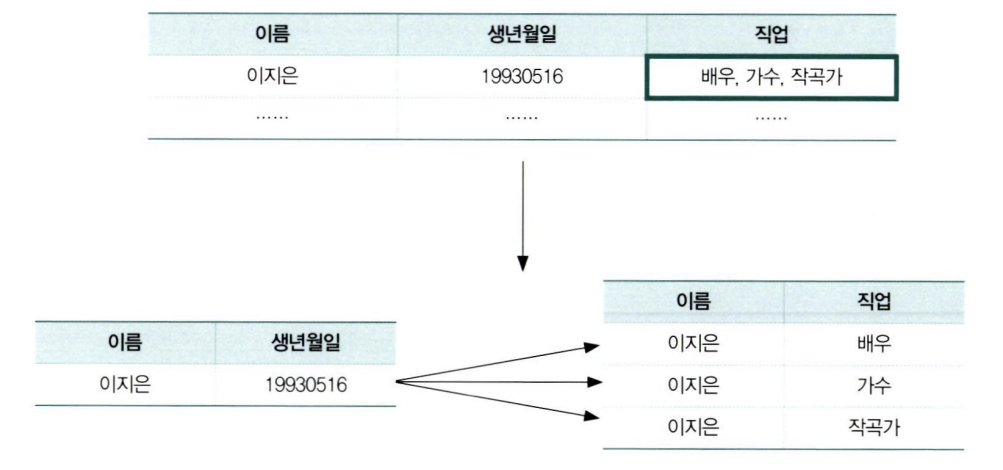
- 유사한 속성이 반복되는 경우도 1차 정규화의 대상이 된다.
애플리케이션에서 데이터를 꺼내 쓸 때 불필요한 Split을 사용해야 하는 번거로움이 생길 수 있기 때문이다.
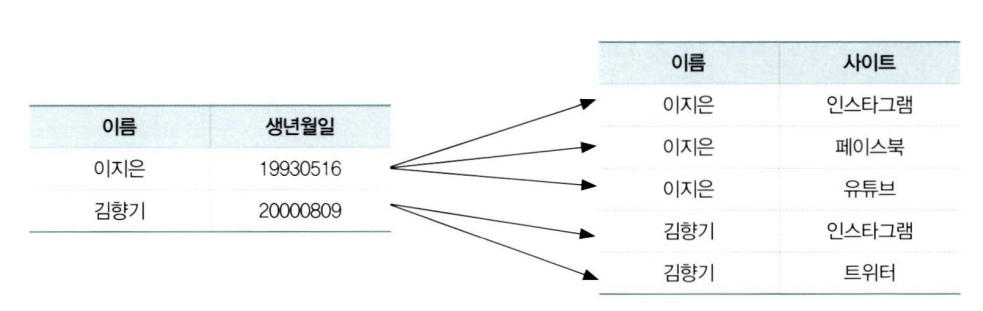
제2정규형
- 엔터티의 모든 일반 속성을 반드시 모든 주 식별자에 종속되어야 한다.
주 식별자가 단일 식별자가 아닌 복합 식별장인 경우 주 식별자의 일부에만 종속될 수 있는데 이런 경우 발생하는 문제점은 아래와 같다.
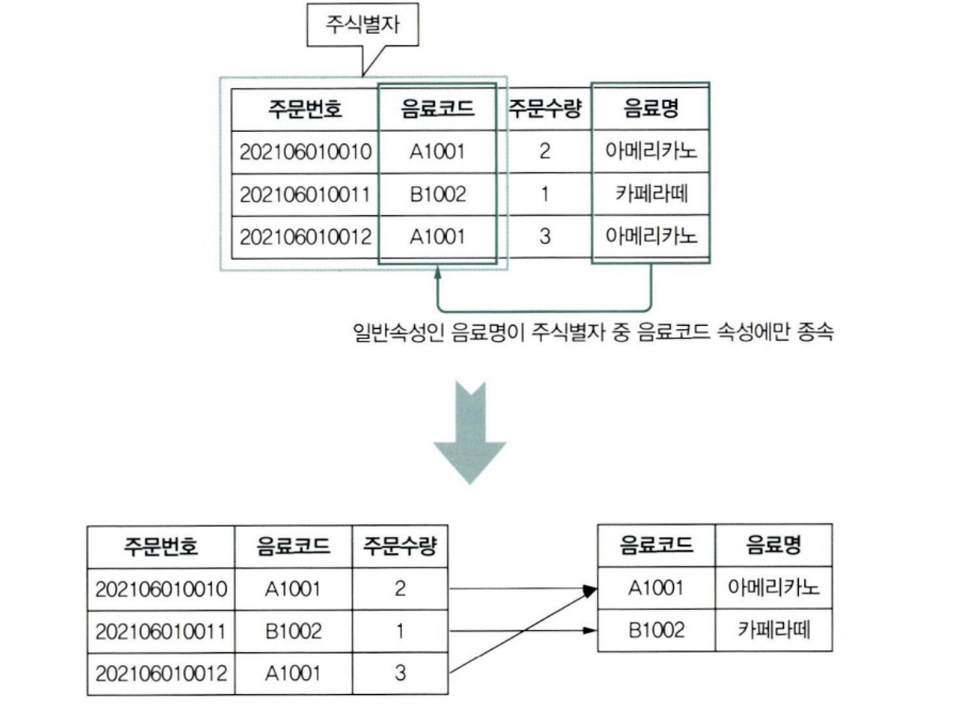
- 입력 이상 현상: 주문이 되지 않은 음료는 입력할 수 없는 경우
- 수정 이상 현상: 음료명이 변경될 경우 해당 음료에 대한 주문 데이터가 모두 변경되어야 하는 경우
2차 정규화를 통해 일반 속성 음료명이 주 식별자 중 음료 코드 속성에만 종속하게 된다면,
바닐라라떼와 같은 음료가 주문이 들어오지 않아도 테이블에 저장할 수 있게 되고
주문 내역 상에서 음료명을 모두 변경하지 않아도 간편하게 음료명을 변경하여 데이터 일관성을 유지할 수 있게 된다.
제3정규형
- 주 식별자가 아닌 모든 속성 간에는 서로 종속될 수 없다.
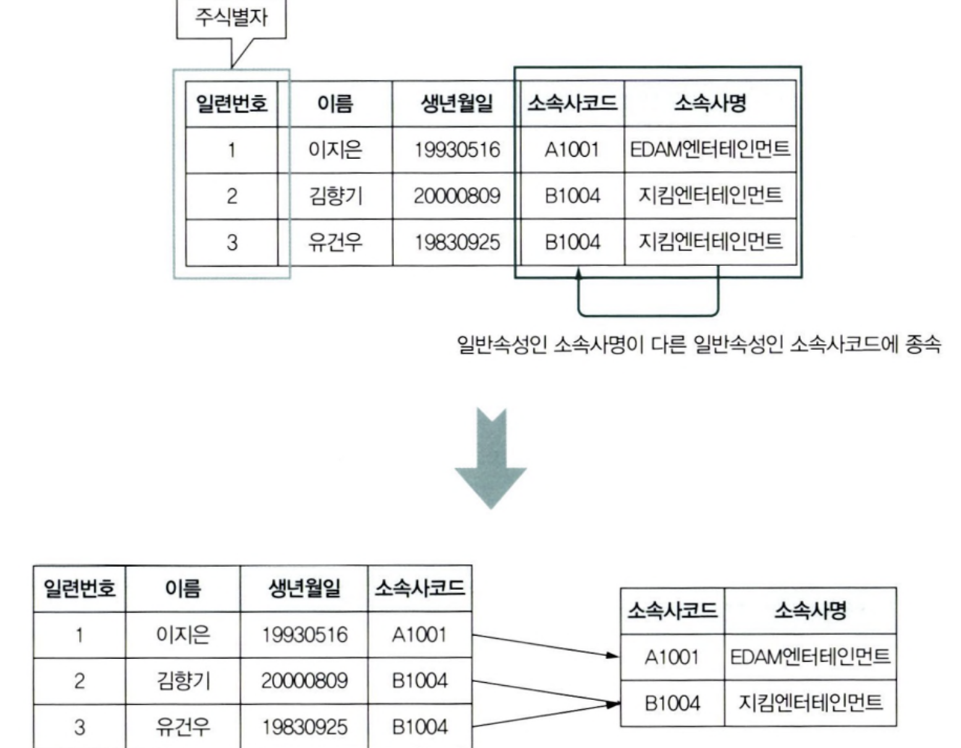
사람에 대한 인적사항을 저장하는 테이블에 그 사람의 소속사에 대한 정보가 저장되어 있다.
이를 분리해 줘야 한다.
02. 반정규화
데이터의 조회 성능을 향상시키기 위해 데이터의 중복을 허용하거나 데이터를 그룹핑 하는 과정
반정규화 과정은 정규화가 끝난 후 거치게 된다.
정규화와 마찬가지로 조회 성능은 향상될 수 있으나 입럭, 수정, 삭제 성능을 저하될 수 있으며 데이터 정합성 이슈가 발생할 수 있고 따라서 일정한 룰이 존재한다.
테이블 반정규화
- 테이블 병합
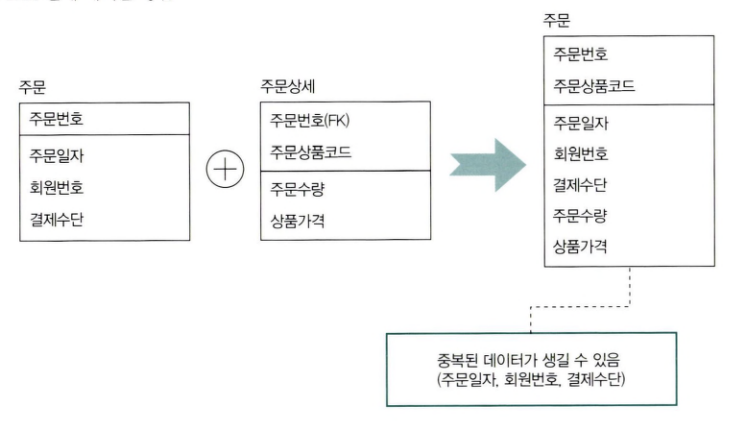
1:M 관계 테이블 병합의 경우 1쪽에 해당하는 엔터티의 속성 개수가 많으면 병합했을 경우 중복 데이터가 많아지므로 테이블 병합에 적절하지 못하다.
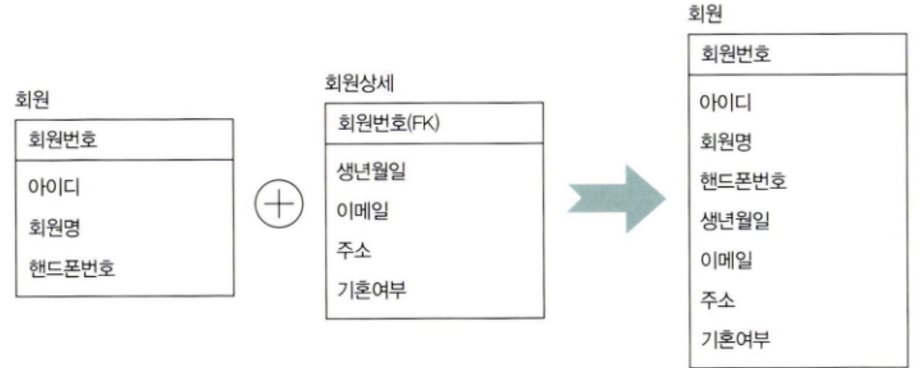
1:1 업무 프로세스상 JOIN이 필요한 경우가 많아 테이블을 통합하는 것이 성능 측면에서 유리할 경우 고려한다.- 1:1 관계 테이블 병합
- 1:M 관계 테이블 병합
- 테이블 분할
- 테이블 수직 분할
- 엔터티의 일부 속성을 별도의 엔터티로 분할(1:1 관계 성립)
- 테이블 수평 분할
- 엔터티의 인스턴스를 특정 기준으로 별도의 엔터팅로 분할(파티셔닝)
- 테이블 수직 분할
- 테이블 추가
- 중복 테이블 추가
- 데이터의 중복을 감안하더라도 성능상 반드시 필요하다고 판단되는 경우 별도의 엔터티 추가
- 통계 테이블 추가
- 통계치를 미리 계산하여 저장
- 이력 테이블 추가
- 과거 이력에 대한 데이터 관리
- 부분 테이블 추가
- 데이터 다량으로 생길 경우 필요 정보만 부분 테이블로 생성
- 중복 테이블 추가
컬럼 반정규화
- 중복 컬럼 추가
- 업무 프로세스상 JOIN이 필요한 경우가 많아 컬럼을 추가하는 것이 유리할 경우 고려
- 파생 컬럼 추가
- 프로세스 수행 시 부하가 염려되는 계산값을 미리 컬럼으로 추가하여 보관하는 방식
- 재고나 프로모션 적용 할인가 등
- 이력 테이블 컬럼 추가
- 대량의 이력 테이블을 조회할 때 속도가 느려질 것을 대비하여 조회 기준이 될 것이로 판단되는 컬럼을 미리 추가
- 최신 데이터 여부 등
관계 반정규화(중복 관계 추가)
- 업무 프로세스상 JOIN이 필요한 경우가 많아 중복 관계를 추가하는 것이 성능 측면에서 유리할 경우 고려
03. 트랜잭션
데이터 조작하기 위한 하나의 논리적인 작업 단위
📍 트랜잭션 예시
퀴즈의 정답을 맞히면 쿠폰을 즉시 방행하는 이벤트, 쿠폰은 선착순 100명 지급
- 이벤트 응모 이력 저장
- 쿠폰 발행 위 작업을 논리적으로 하나의 단위로 묶어야 한다.
04. NULL
NULL은 존재하지 않음, 즉 값이 없음을 의미한다. 0이랑 엄연히 다른 데이터이다.
- 가로 연산 - NULL 값 포함되어 있으면 결과값 NULL
- 세로 연산 - NULL 값은 제외하여 연산
'DataBase > Study' 카테고리의 다른 글
| [SQLD] SQL 활용 (0) | 2024.05.22 |
|---|---|
| [SQLD] SQL 기본 (0) | 2024.04.09 |
| [SQLD] 데이터 모델링의 이해 (1) | 2024.03.26 |

